-

- 商品一覧
- 価格帯別商品一覧
- 学生向け商品一覧
-
文献管理
EndNote - 新規ライセンス
- アップグレード
- 年間ライセンス
-
質的研究支援
NVivo - NVivo
- 新規購入
- サブスクリプションライセンス
- 学生用
- グループライセンス
- NVivo ガイドブック
- NVivo アドオン製品
- NVivo Transcription
-
統計解析
IBM SPSS Statistics - 【保守付き】
- 【推奨構成】【教育機関/臨床研修病院向け】
- 【推奨構成】【官公庁向け】
- 【推奨構成】【一般向け】
- 【モジュール】【教育機関/臨床研修病院向け】
- 【モジュール】【官公庁向け】
- 【モジュール】【一般向け】
- 【年間ライセンス】
- 【推奨構成】【教育機関/臨床研修病院向け】
- 【推奨構成】【一般向け】
- 【モジュール】【教育機関/臨床研修病院向け】
- 【モジュール】【一般向け】
- 【保守なし】
- 【推奨構成】【教育機関/臨床研修病院向け】
- 【推奨構成】【一般向け】
- 【モジュール】【教育機関/臨床研修病院向け】
- 【モジュール】【一般向け】
- 学生版
- アドオン
- コンカレントライセンス
-
統計解析
IBM SPSS Amos -
統計解析
SPSS オンライントレーニング -
統計解析・グラフ作成
GraphPad Prism - 日本語アドオンセット(Windows)
- 英語版
-
統計解析・グラフ作成
KaleidaGraph -
統計解析・データ分析
XLSTAT - XLSTATライセンス
- XLSTATオプション
-
統計解析
EXCEL統計 -
テキストマイニング
Text Mining Studio -
データマイニング
Alkano -
ノーコードAI解析プラットフォーム
Multi-Sigma -
シミュレーション
S4 Simulation System -
AI自動翻訳
T-4OO -
医学翻訳
MED-Transer -
翻訳
PC-Transer -
医学翻訳
翻訳ピカイチ メディカル -
コピペ判定支援
コピペルナー -
文献管理・思考整理
Citavi -
研究データ管理
LabSecretary -
ファイル管理/ストレージ
pCloud -
学術ポスター制作ツール
ポサコ -
科学画像検証システム
Proofig AI - その他パソコンソフト
-
英文校正
editage - 学術ジャーナル
- 書籍
-

-
文献管理
EndNote - 文献管理機能
- 論文作成支援機能
- 同期・共有機能
- 無料オンラインセミナー
- 文献管理ソフトとは?
- EndNote使用ヒント集
- EndNoteのグループ機能を活用してみよう
- ライブラリ内のレコードにメモを付ける
- ライブラリデータのバックアップを作成しよう
- EndNoteの同期機能を活用しよう
- EndNote Capture Reference Toolを使って、Webページの情報や文献情報を取り込む
- 論文を読むのに便利 EndNote for iOSを始めよう
- 書籍の情報を取り込む
- エクセルに文献情報を出力する
- EndNoteをシステマティックレビューに活用する
- ライブラリ内の重複文献を削除しよう
- 日本語と英語が混在する投稿規定の論文を作成する
- EndNote の共有(Share)機能を使用して共同研究環境をつくる
-
質的研究支援
NVivo - NVivo 分析機能
- NVivo 可視化機能
- NVivo 管理機能
- NVivo アンケートデータ分析支援機能
- NVivo SNS分析支援
- NVivo Windows Mac 機能比較表
- NVivo 無料トライアル版ダウンロード
- NVivo 動画版 クイックスタートガイド
- NVivo 無料ウェブセミナー
- QDAソフトとは?
- QDAソフトの利点 メリット・デメリット
- QDAソフトは質的分析をするのか?
- NVivo 自動コーディング 発言者ごとのコーディング
- 質的研究に適しているのはQDAソフトか?テキストマイニングソフトか?
- NVivoにアンケートを取り込んで分析をしてみよう
- 質的データの視覚化と使い方
- NVivoでコードのKJ法的分類・整理をおこなう
- コーディングストライプ使用方法トップ10
- 先行研究・論文レビューにNVivoを活用する
- NVivoで修正版グラウンデッド・セオリー・アプローチ(M-GTA) 分析ワークシートを作成する
- NVivoとEndNoteを使った文献レビューの最適化
- 回答者ごとに特定テーマに対する発言内容をまとめるーフレームワーク行列
- 質的コーディングの技術を高める
- 健全なNVivoプロジェクトの秘訣
- NVivoは社会変革をどのように支援できるか
- 質的データはどのように数値化できるか:あなたのデータの価値
- インタビューデータの主題分析: NVivoが役立つ6つの方法
- 質的研究の信頼性をどのように評価するか?
- 文献レビューでNVivoのスキルを磨く
- 評価者間信頼性テストの落とし穴を避ける
- 混合研究法-研究者の間で広がる方法論
- NVivo 活用事例インタビュー
- NVivoを使用した文献の紹介
- NVivo 動画ガイド
- NVivo ワークショップ
- プロジェクト共有 NVivo Collaboration Cloud
- 自動文字起こし NVivo Transcription
-
統計解析
IBM SPSS Statistics - パッケージ・モジュールの選び方
-
統計解析・グラフ作成
KaleidaGraph -
テキストマイニング
Text Mining Studio - Text Mining Studio、機能とサポートが高評価の訳
- TMS活用事例 - Tech Trend Analysis 有門経敏 様 インタビュー
-
データマイニング
Alkano -
シミュレーション
S4 Simulation System -
AI自動翻訳
T-4OO -
自動文字起こし
NVivo Transcription -
英文校正
editage - エディテージ x ユサコの論文執筆ヒント集
- 読者の理解度を向上させる「IMRAD形式」の論文構成とは?
- 論文を投稿するジャーナルの選び方とは?
- 英語の類義語の使い分け出来ていますか?
- 質的医療研究を報告する際に覚えておきたい5つのこと
- 学会発表を成功させるための8箇条
- 空約束で著者をそそのかす“ハゲタカジャーナル”
- 自身の研究を世界に広めるための8箇条
- 研究の成否のカギは、研究データの管理
- 編集者による不正行為「強制引用」の要求を見分けるには
- 強制引用の要求に対処するには
- 研究の有意性とは?p値に頼るべきでない理由
- 研究助成金申請書を確認することの重要性
- 優れたRebuttal Letter(反論の手紙)をどう書くか?
- 利益相反があるかどうかを判断するための"6つのP"
- 学術出版における剽窃行為
- 査読に関する疑問トップ10
- 若手研究者のためのシステマティックレビューの書き方指南
- 若手研究者のためのオープンアクセス出版ガイド
- 統計的有意性と臨床的意義をつなぐためのパラダイム・シフト
- 研究者が避けるべき4つの統計学的エラー
- オープンアクセスに関する質問トップ8
- 方法セクションの書き方
- ソースの学術性と信頼性を見きわめるためのヒント
- 優れたタイトルとアブストラクト、適切なキーワード選び
- 能動態と受動態を効果的に使うには:前編
- 能動態と受動態を効果的に使うには:後編
- 論文をよりスッキリと簡潔にする10の秘訣
- 剽窃行為を事前に防ぐためにできること
- 研究背景の書き方
- 科学論文における単語選びのミス6タイプ 前編
- 科学論文における単語選びのミス6タイプ 後編
- 学術論文に磨きをかける実践的ヒント6選 前編
- 学術論文に磨きをかける実践的ヒント6選 後編
- 科学論文での略語のミスを避けるためには
- 数値と単位の表記によくあるミス5選
- ジャーナル編集者が文献レビューに求めること
- 論文の初稿を書き上げるには
- カバーレターを成功させるための10の秘訣
- 一流の生物医学誌で論文を出版するための5つの秘訣
- 進化するハゲタカビジネスに対抗するには
- ジャーナル選びのガイド:正しい選択をするために
- 査読プロセスを乗り越えるために欠かせない、投稿前の徹底チェック
- ソーシャルメディアからの情報を学術論文に引用する方法
- 質的研究で避けるべき7つのバイアス
- ネットワーク作りのためのヒント10選
- プレプリントが研究の普及に果たす役割
- 科学を語ろう:研究者が一般市民と交わるべき理由
- 高品質な英語論文を書くためのヒント5選
- 科学論文における時制の使い分け
- インパクトファクターをどう見るか: エキスパート7人の視点
- 透明性が査読不正を食い止める
- 査読コメントへの返信でやっていいこと、ダメなこと
- 査読の依頼を断る理由
- 査読コメントへの返答の仕方に関するアドバイス
- 査読者からの矛盾するコメントにどう対応するか
- リジェクトになる一番多い理由
- ノーベル賞受賞者でも掲載拒否を受けることはある
- 【若手研究者向けガイド】 様々なタイプの論文について
- 論文タイトルを正しく書くための3つのアドバイス
- 書籍『英文校正会社が教える 英語論文のミス 分野別強化編』 内容紹介
- こんな間違いしていませんか? Vol.1 『英文校正会社が教える 英語論文のミス 分野別強化編』 内容紹介
- こんな間違いしていませんか? Vol.2 『英文校正会社が教える 英語論文のミス 分野別強化編』 内容紹介
- こんな間違いしていませんか? Vol.3 『英文校正会社が教える 英語論文のミス 分野別強化編』 内容紹介
- こんな間違いしていませんか? Vol.4 『英文校正会社が教える 英語論文のミス 分野別強化編』 内容紹介
- こんな間違いしていませんか? Vol.5 『英文校正会社が教える 英語論文のミス 分野別強化編』 内容紹介
- 書籍『英文校正会社が教える 英語論文のミス100』 内容紹介
- こんな間違いしていませんか? Vol.1 『英文校正会社が教える 英語論文のミス100』 内容紹介
- こんな間違いしていませんか? Vol.2 『英文校正会社が教える 英語論文のミス100』 内容紹介
- こんな間違いしていませんか? Vol.3 『英文校正会社が教える 英語論文のミス100』 内容紹介
- こんな間違いしていませんか? Vol.4 『英文校正会社が教える 英語論文のミス100』 内容紹介
- こんな間違いしていませんか? Vol.5 『英文校正会社が教える 英語論文のミス100』 内容紹介
- editage 研究者向けワークショップ
-
医学翻訳
MED-Transer -
コピペ判定支援
コピペルナー - コピペをすることのリスクについて
- 『コピペルナー』開発のきっかけ
- コピペルナーのコピペチェックのしくみ
-
研究データ管理
LabSecretary - 管理機能詳細
-
ファイル管理/ストレージ
pCloud -
学術ポスター制作ツール
ポサコ -

-

- ご利用ガイド
- EndNoteをご検討の方
- 公費、科研費、請求書払いをご希望の方
- 各製品のアカデミック価格対象
- エクセル申込書でのご注文の方(代理購入含む)
-

- EndNoteユーザー登録
- 見積依頼
- お問い合せフォーム
- 商品購入に関するお問い合わせ
- その他のお問い合わせ
論文作成支援・統計解析・翻訳・学術研究のためのショッピングサイト





『コピペルナー』のコピペチェックのしくみ
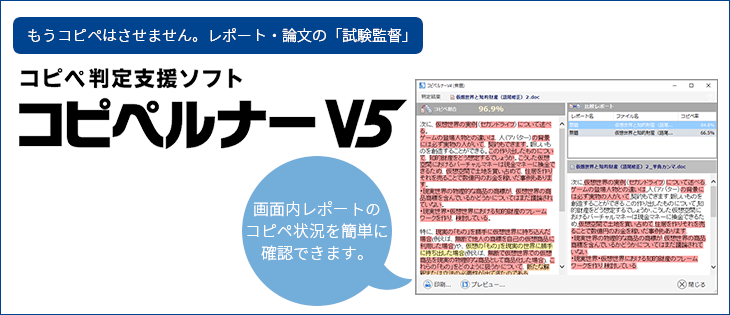
学生・部下からのレポートのチェックにコピペがないか頭を悩ませていませんか?
今回は、コピペルナーが実際にどのような動作で剽窃チェックをおこなっているのか紹介します。
チェックできる文書とできない文書
- 【チェックできる文書】
- ●インターネットの検索エンジンで検索できる文書
- ●チェック対象としてコピペルナーに同時に登録した文書同士
- ●過去にコピペルナーでチェックして保存済みの文書
- ●コピペルナーの文献登録機能で予め登録してある文書
- 【チェック対象外の文書】
- ●紙に印刷されている文書
- ●インターネット上に存在しているが、アクセスに認証が必要な文書
今回は、コピペルナーが実際にどのような動作で剽窃チェックをおこなっているのか紹介します。
紙の文書をチェックするには、OCR(光学文字認識)ソフトで紙文書の画像をテキストデータに変換し、そのデータをコピペルナーで読み込ませる必要があります。
また、コピペルナーでチェックできるのはテキストデータのみなので、画像、図、グラフなどはチェック対象外です。
コピペチェックの流れ
コピペルナーは、次のような手順でコピペチェックを行っています。
- チェック対象として読み込んだ文書から、重要な単語や、重要な単語を多く含む文節(重要文節)を自動的に抽出し、検索キーワードに設定します。検索キーワードは、ユーザー自身で手動設定することもできます。
- 設定された検索キーワードを使って、Google検索を行い、複数のWebページを取得します。
- 取得した複数のWebページについて、そのページ内容をダウンロードします。ダウンロードしたデータがテキスト形式以外(Word、PDFなど)の場合、テキスト形式に変換されます。
- チェック対象として読み込んだ文書とダウンロードしたデータの内容を、文節単位で比較します。日本語辞書を搭載しつつ、形態素解析を行うことで、日本語のチェック精度を高めております。
- コピペ割合について、文節単位で算出します。
コピペチェックのカスタマイズ
コピペルナーは目的に合わせてカスタマイズすることが可能です。
チェックするページ、キーワードを手動で設定することで、より精度の高いコピペチェックが可能になります。
- ●コピペルナーが自動抽出したキーワード以外にも手動でキーワードを追加可能。
- コピペルナーは設定したキーワードを検索し、読み込んだレポートと比較するため、キーワードの設定次第で判定結果が変わってきます。自動抽出に加えて任意のキーワードを設定することで、より精度の高い判定が可能になります。
- ●特定ドメイン・サイトのチェックが可能
- Wikipediaは学生が参考にする確率が高いため、デフォルトで検索対象に指定されています。
これ以外にも、課題に対して学生が見に行くサイトが予想できれば予め指定しておくことで、判定に役立てることが出来ます。 - ●コピぺ判定比較対象として取得するURL数、PDF数は設定変更可能。
- HTML:初期設定30ページ 最大100ページ
- PDF:初期設定10ページ 最大50ページ
まとめ
コピペルナーはレポート・論文の監督という役割であり、不正を暴くツールではありません。
考案者の杉光教授の願いは「考える力や表現する力を養ってほしい」というものです。
コピペルナーはあくまで著作物を正しく扱い、将来間違った行為を行わないように指導するための支援ツールです。






- 文献管理・論文作成支援
- EndNote
- 新規ライセンス
- アップグレード
- 年間ライセンス
- 文献管理・思考整理
- Citavi
- Citavi 買切版
- Citavi サブスクリプション版
- Citavi アドオン
- 統計解析
- IBM SPSS Statistics
- 【保守付き】
- 【推奨構成】【教育機関/臨床研修病院向け】
- 【推奨構成】【官公庁向け】
- 【推奨構成】【一般向け】
- 【モジュール】【教育機関/臨床研修病院向け】
- 【モジュール】【官公庁向け】
- 【モジュール】【一般向け】
- 【サブスクリプション】
- 【推奨構成】【教育機関/臨床研修病院向け】
- 【推奨構成】【一般向け】
- 【モジュール】【教育機関/臨床研修病院向け】
- 【モジュール】【一般向け】
- 【保守なし】
- 【推奨構成】【教育機関/臨床研修病院向け】
- 【推奨構成】【一般向け】
- 【モジュール】【教育機関/臨床研修病院向け】
- 【モジュール】【一般向け】
- 学生版
- アドオン
- コンカレントライセンス
- 教育機関/臨床研修病院向け・保守契約なし
- 一般・保守契約なし
- IBM SPSS Amos
- SPSS オンライントレーニング
- GraphPad Prism
- 日本語アドオンセット(Windows)
- 英語版
- KaleidaGraph(カレイダグラフ)
- XLSTAT
- XLSTATライセンス
- 【新規】教育機関向け
- 【新規】一般向け
- 【継続】教育機関向け
- 【継続】一般向け
- XLSTATオプション
- 教育機関向け
- 一般向け
- EXCEL統計
- データマイニング
- Alkano
- Multi-Sigma
- シミュレーション
- S4 Simulation System
- テキストマイニング
- Text Mining Studio
- TMS 研究者・研究室向けライセンス
- 質的研究・定性調査
- NVivo
- NVivo
- 買切版
- サブスクリプション版
- 学生版
- グループライセンス
- NVivo Transcription
- NVivo アドオン製品
- 翻訳
- オンラインAI自動翻訳 T-4OO
- MED-Transer
- PC-Transer
- 翻訳ピカイチ
- 剽窃チェック
- コピペルナー
- 研究画像不正検出サービス
- Proofig AI
- 研究データ管理ソフト
- LabSecretary
- その他パソコンソフト
- 英文校正・論文投稿
- editage
- 学術ジャーナル
- 書籍
- ファイル管理/ストレージ
- pCloud



shop@usaco.co.jp
 当社では、個人情報を取り扱うために必要なプライバシーマークを取得しております。
当社では、個人情報を取り扱うために必要なプライバシーマークを取得しております。

